こんにちは!エンジニア3年生!開発部の藤川です。文字化けした文書ってちょっと面白いですよね。
ですが、今回は文字化けした文書を作り出さないようにするお話です。
業務システムの開発ではCSVを扱うことが多いです。一方で、システムの利用環境(多くの場合はWindows)と、開発環境(MacやLinux)の差異によって、CSVファイルを扱うときに「文字化け」や「改行がうまく反映されない」などの問題が生じることもしばしばあります。実際に私も改行コードのことを考えずCSVを作成し、改行が反映されなかったことがあります。
本記事では、プログラミング初心者でもわかるよう、Pythonのライブラリであるpandasを使ったCSVファイル作成の注意点をご紹介します。
具体的には、文字コードと改行コードの2つの落とし穴について取り上げながら、開発環境(MacやLinux)と利用環境(Windows)が異なる場合にどのようなトラブルを防ぐことができるのかを解説します。どちらもとても基本的なことではありますが、うっかり設定を忘れてしまうと後から手痛い修正が必要になったり、苦情を受けたりする原因にもなりかねません。
pandasを初めて使う人や、「今さら人には聞きづらい!」という人の参考になれば嬉しいです。
pandasとは
pandas(パンダス)は、Pythonでデータ分析やデータ操作をする際に欠かせない人気ライブラリのひとつです。
大きな特徴としては、行と列から成る「DataFrame」という構造でデータを扱うことで、2次元のデータを柔軟に加工・分析できる点が挙げられます。今回のテーマであるCSVの読み書きに関しても、pandasを使うと非常にシンプルなコードで実装できます。
たとえば、read_csv関数を用いればCSVファイルを簡単に読み込み、to_csv関数を用いれば簡単にCSVを書き出すことができます。もともとPythonには標準ライブラリとしてcsvモジュールがありますが、pandasを使うと列名やインデックス名などが扱いやすく、行列としての操作もしやすいので、より複雑な処理をしたいときにも便利です。
主な機能
pandasでCSVを扱うことで、下記のようなことができます。
pandasでできること
- CSV読み書き read_csvやto_csvを使えば、最小限のコードでCSVファイルを読み書きできます。
- バリデーション CSVなどで外部から取り込んだデータに対して、NaN(空の値)や異常値などを検知しやすいです。データ整合性を確認する際に便利です。
- 豊富なデータ操作メソッド グルーピング(groupby)や集計(agg, sum, meanなど)はもちろん、マージ(merge)や結合(join)など、大量のデータを扱うのに便利な機能を備えています。
pandas自体の使い方については、公式ドキュメントや他の技術ブログなどにも多数の情報があります。基本的な操作方法を知りたい方は調べてみてください。
開発環境と利用環境が異なる場合の落とし穴
今回注目したいのは、開発環境(MacやLinux)と実際にシステムを利用する環境(多くの場合Windows)が異なる場合です。プログラムを開発する際は、個人のPC(MacやLinux)が使われることも多い一方で、業務システムが動く環境はWindowsベースだったりするのが一般的です。この環境差によって起こりがちな落とし穴が以下の2つです。
- 文字コードの問題 開発環境で作成したCSVは読み書きができるのに、Windows環境で作ったCSVは正常に読み書きできない。
- 改行コードの問題 システムが作ったCSVをWindowsで開くと、改行が正しく認識されずに1行にまとまってしまうなどのトラブルが起きる。
これらはいずれも、「作ったCSVファイルがWindowsで正しく表示されない」「Excelで開くと見た目が崩れる」などの困りごとにつながりやすい問題です。しかも、ほんの少し設定するだけで回避できるため、「なんとなく動くからいいや」と放置していると、運用フェーズに入ってからトラブルとなる可能性があります。
落とし穴その1:文字コード
文字コードとは
文字コードとは、コンピュータがバイナリデータをどの文字として解釈するかを決める取り決めのことです。一般的に使われる文字コードとしては、以下のようなものがあります。
- UTF-8 LinuxやMacなどの環境、そしてGoogleスプレッドシートなどでも標準的に利用されています。日本語以外も幅広くカバーでき、国際的に標準化されているため、近年はこちらが主流になりつつあります。
- Shift_JIS(CP932) Windowsの日本語環境で古くから使われてきた文字コードです。厳密にいえば「CP932はMicrosoft独自の拡張Shift_JIS」という位置づけなので、Shift_JISとCP932が全く同じというわけではありません。ただし、Windows環境で「日本語のExcelで開く」ことを前提とする場合は、CP932を指定しておけば無難です。特殊文字が多いと文字化けする可能性もありますが、レガシーなシステムと連携するときには避けられない場合もあります。
実は私自身も、「作成したCSVを開こうとしたら、何がなんだか分からない記号が並んでいて読めない!」と頭を抱えた経験があります。開発環境では問題なくても、デコード方法が違う別の環境で開くと文字化けを起こします。
サンエルでは、CSVの作成や確認にGoogleスプレッドシートを使う機会が多いですが、ユーザーからは「Excelで作成している」「Excelで確認したい」といった要望がよく寄せられます。GoogleスプレッドシートはUTF-8、ExcelはShift_JIS(CP932)というように、標準的な文字コードが異なります。そのため「文字コードを常に意識してCSVをやりとりする」ことが欠かせません。
文字コードの確認方法
文字コードの確認はいくつかの方法があります。ここでは代表的な2つをご紹介します。
- VSCodeを使う方法
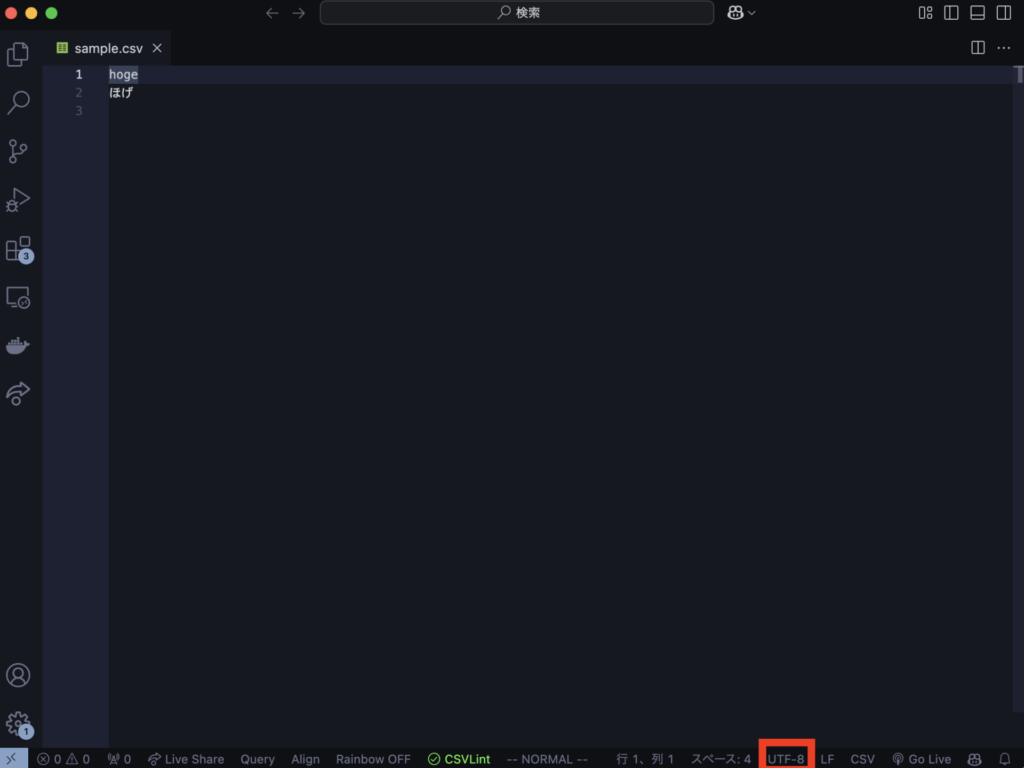
Visual Studio Codeでファイルを開くと、右下に文字コードを表す部分があります。「UTF-8」「Shift JIS」などと表示されますが、完璧に正確なわけではないので注意が必要です。 ここをクリックすると他の文字コードに変換することもできます。
- ターミナルを使う方法

MacやLinuxのターミナル上で、fileコマンドを実行すると、ファイルのエンコーディングをある程度推測して表示してくれます。たとえば、
$ file sample.csvと打つと、UTF-8 Unicode textのように、推定される文字コードが表示されることがあります。ただし、完全に正確に判定してくれるわけではない場合もあります。
実際の現場ではVSCodeなどのエディタで確認する方が手軽かもしれません。エディタによっては、保存時に文字コードを指定できるので、そのときにUTF-8からShift JIS(CP932)へ変換するといった操作も簡単にできます。
pandasでの指定方法
pandasを使ってCSVファイルを書き出す場合、文字コードを指定するのはとても簡単です。DataFrame.to_csvにencoding引数を与えるだけでOKです。たとえば、以下のように記述します。
df.to_csv("sample.csv", encoding="cp932")こうすると、Windows環境のExcelで開いたときに文字化けしにくいCSVを生成できます(日本語を含むデータを想定)。逆に、MacやLinuxなどで扱うことが前提の場合や、国際的に標準的な文字コードを使いたい場合は、以下のようにUTF-8を明示指定するとよいでしょう。
df.to_csv("sample_utf8.csv", encoding="utf-8")また、CSVを読み込む際はread_csv("ファイル名", encoding="文字コード")のように指定することも可能です。外部から受け取ったCSVファイルが文字化けしてしまうときは、正しいエンコーディングを指定して再読み込みしてみると問題が解決する場合があります。
落とし穴その2:改行コード
改行コードとは
改行コードとは、テキストファイルで行を区切るための制御文字です。代表的なものは以下の3種類です。
- LF (\n) LinuxやMacなどでは、改行としてLF(Line Feed)を利用します。
- CR(\r) 古いMac OSでは、改行としてCR(Carriage Return)が利用されていました。
- CRLF (\r\n) Windowsでは改行としてCRとLFの組み合わせを利用します。
この違いにより、Linux/Macで編集したファイルをWindowsに持っていくと、一行にズラーッとテキストが並んでしまったり、逆にWindowsで作成したファイルをLinux/Macで扱うと、改行が余計に入ったり表示が乱れたりといった問題が発生することがあります。
改行コードの確認方法
改行コードもVSCode・ターミナル両方で確認できます。
- VSCodeを使う方法
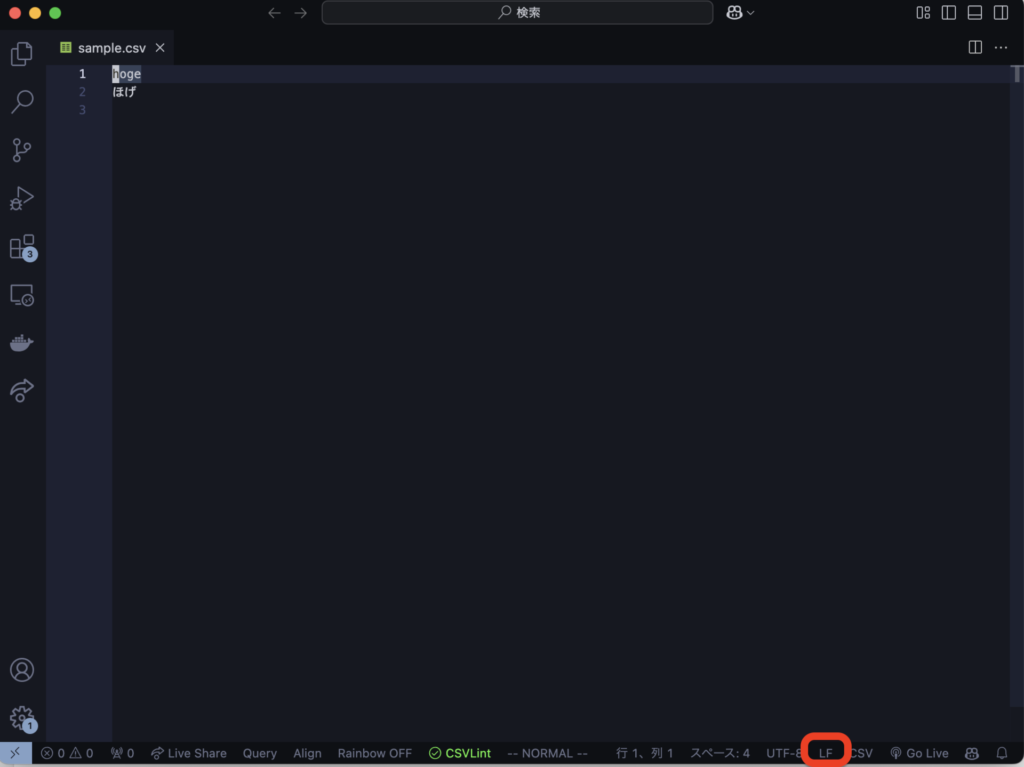
文字コード同様、右下に「LF」で保存しているのか「CRLF」で保存しているのかが表示されます。必要に応じて手動で変換することも可能です。
- ターミナルを使う方法
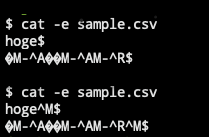
上が改行コードLFのファイル、下が改行コードCRLFのファイルの結果 ファイルの内容を表示するcatコマンドにオプションを追加することで改行コードを確認できます。
$ cat -e sample.csv 上記のコマンドで、テキストの行末に改行コードが記号化されて表示されます。 -eオプションは通常では印字されない改行コードを表示するオプションです。
| 改行コード | 改行記号 | 正規表現 |
|---|---|---|
| LF | $ | \n |
| CR | ^M | \r |
| CRLF | ^M$ | \r\n |
pandasでの指定方法
pandasではto_csvにlineterminator引数を与えることで改行コードを指定できます。
たとえば、Windows用にCRLFを指定したい場合は以下のようになります。
df.to_csv("sample_windows.csv", encoding="cp932", lineterminator="\r\n")このように設定すると、Windowsで開いたときにも改行が正しく認識されやすくなります。逆に、通常のLinuxやMacの環境で扱いたい場合はLF(\n)を指定しておけば問題ありません。
df.to_csv("sample_linux.csv", encoding="utf-8", lineterminator="\n")何も指定しなかった場合は、OSに合わせた改行コードを指定してくれます。
まとめ
CSVを扱うとき、pandasは非常に便利なライブラリです。簡単なデータ処理から大規模な分析まで広範囲に活用でき、CSV読み書きも一行二行のコードで完結できてしまうのは大きな魅力といえます。一方で、開発環境と利用環境が異なる場合、文字コードや改行コードの指定をうっかり忘れると、Windowsで開いたときに文字化けしたり改行が崩れたりといったトラブルが起こる可能性があります。
CSVファイルはExcelや業務アプリケーションとやりとりをするときの橋渡し的存在で、DX推進の現場で特に多用されるフォーマットです。もし、「なんでWindowsで開くとこんな風に文字化けするんだ?」とか「改行が全部消えちゃってる!」という事態に遭遇したときは、ぜひ本記事の内容を思い出してみてください。